vllm-omni
vLLM-Omni 是一个面向全模态(Omni-modality)模型推理与服务的框架,旨在为用户提供 简单、快速、低成本 的多模态模型部署方案。它扩展了原生 vLLM 对文本生成的支持,覆盖 文本、图像、视频、音频 等多模态数据处理,并支持 DiT 等非自回归架构,实现 异构输出(如多模态内容生成)。
核心设计
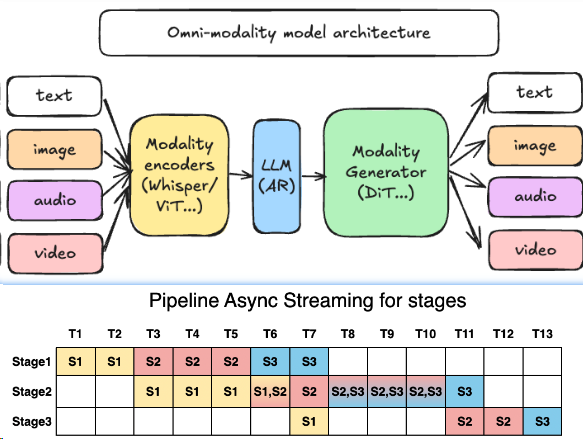
解耦式流水线:分阶段动态分配资源,实现高吞吐与低延迟:[^4]
- 模态编码器(Modality Encoders):负责高效地把多模态输入编码成向量或中间表示,例如 ViT 视觉编码器、Whisper 等语音编码器。
- LLM 核心(LLM Core):基于 vLLM 的自回归文本 / 隐藏状态生成部分,可以是一个或多个语言模型,用于思考、规划和多轮对话。
- 模态生成器(Modality Generators):用于生成图片、音频或视频的解码头,例如 DiT 等扩散模型。
这些组件并不是简单串联,而是通过 vLLM-Omni 的管线调度在不同 GPU / 节点间协同工作。对于工程团队来说,这意味着:
- 可以针对不同阶段单独做扩缩容和部署拓扑设计;
- 可以根据业务瓶颈(如图像生成 vs 文本推理)调整资源分配;
- 可以在不破坏整体架构的前提下替换局部组件(例如切换为新的视觉编码器)。
核心优势
- 高性能[^4]
- 继承 vLLM 的高效 KV 缓存管理,优化自回归任务性能
- 通过流水线阶段执行重叠提升吞吐量
- 基于 OmniConnector 的动态资源分配与解耦架构
- 易用性与灵活性
- 异构流水线抽象管理复杂模型工作流
- 无缝集成 Hugging Face 模型库
- 支持分布式推理(张量/流水线/数据/专家并行)
- 提供流式输出与 OpenAI 兼容 API
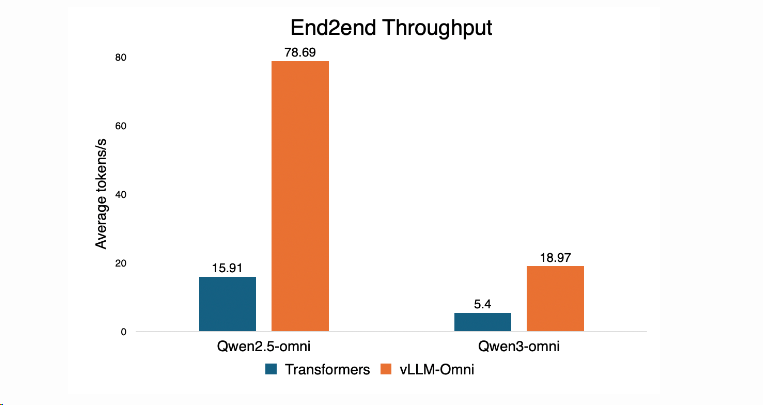
性能收益
相对于transformers推理有 3.5x ~ 4.9x的提升。[^4]
支持模型
文档说明链接
- Omni-modality models (e.g. Qwen2.5-Omni, Qwen3-Omni)
- Multi-modality generation models (e.g. Qwen-Image)
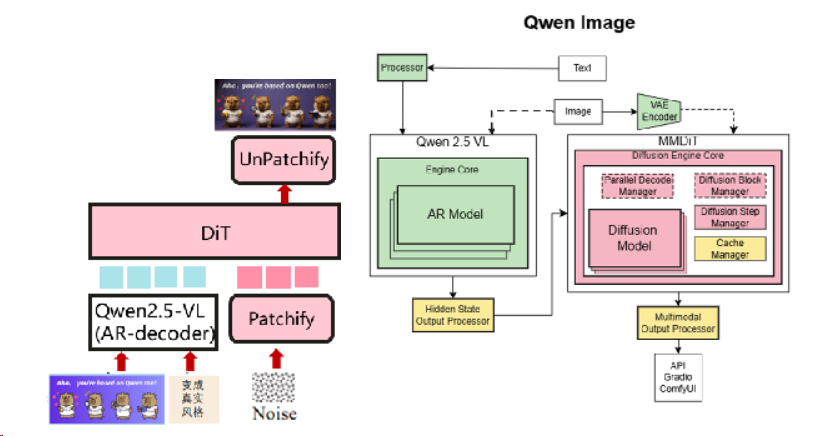
架构设计
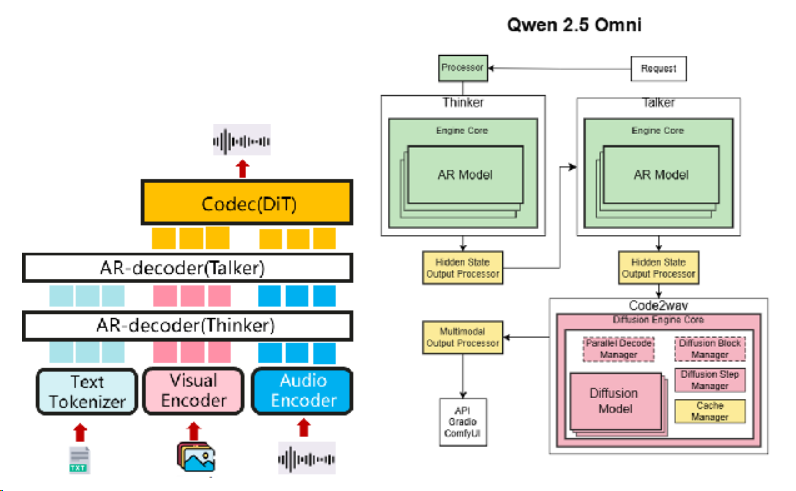
Vllm-omni将从现有的vLLM框架中导入核心模块(LLM),并引入几个新的组件(DiT)和修改(调度器)以实现其目标。核心架构将基于模块化设计,允许独立开发和集成不同的模态处理程序和输出生成器。
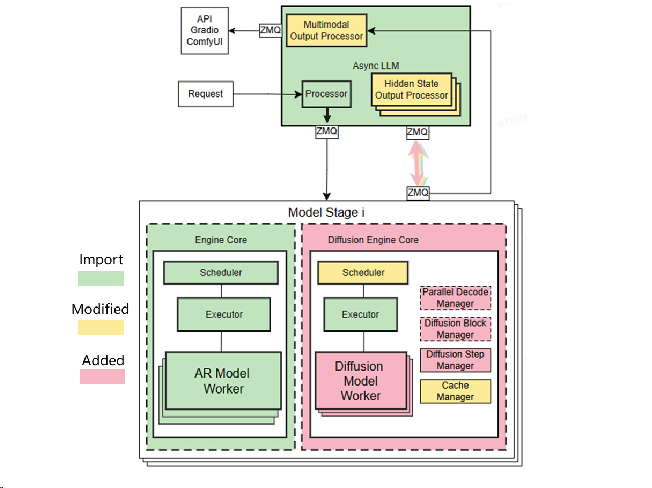
Qwen-omni
Qwen-Image
RoadMap
规划模型
配套支持
NPU
文档是说是能原生支持的^3, 但是上手实测还是跑不通,issue
VeRL+vllm omni
- 一方面, VeRL还不支持Qwen-Omni系列^1, 主要难点在支持音频, 相关PR^2
- 另一方面,VeRL能不能无缝的从vllm后端切换到vllm-omni后端
- 最后,本身就跑不通,更不用说接VeRL了。
TODO: 可以拉PR看能不能切换到vllm-omni
代码走读
以qwenImage为例子 vllm-omni\examples\offline_inference\qwen_image\text_to_image.py
1 | from vllm_omni.entrypoints.omni import Omni |
类似xxx=LLM()的接口
TODO: 如何和设计耦合的
新模型接入
以QwenImage的主PR为例
文件太多了,没跑通前,太难看了。
性能实测
如何获得解耦流水线收益
profiling
参考文献
[^4]: Announcing vLLM-Omni: Easy, Fast, and Cheap Omni-Modality Model Serving